高可用IP代理池
本项目所采集的IP资源都来自互联网,愿景是为大型爬虫项目提供一个高可用低延迟的高匿IP代理池。
项目亮点
- 代理来源丰富
- 代理抓取提取精准
- 代理校验严格合理
- 监控完备,鲁棒性强
- 架构灵活,便于扩展
- 各个组件分布式部署
快速开始
注意,代码请在release列表中下载,master分支的代码不保证能稳定运行
单机部署
服务端
- 安装Python3和Redis。有问题可以阅读这篇文章的相关部分。
- 根据Redis的实际配置修改项目配置文件config/settings.py中的
REDIS_HOST、REDIS_PASSWORD等参数。 - 安装scrapy-splash,并修改配置文件config/settings.py中的
SPLASH_URL - 安装项目相关依赖
pip install -r requirements.txt
- 启动scrapy worker,包括代理IP采集器和校验器
python crawler_booter.py –usage crawler
python crawler_booter.py –usage validator
- 启动调度器,包括代理IP定时调度和校验
python scheduler_booter.py –usage crawler
python scheduler_booter.py –usage validator
客户端
近日不断有同学问,如何获取该项目中可用的代理IP列表。haipproxy提供代理的方式并不是通过api api来提供,而是通过具体的客户端来提供。
目前支持的是Python客户端和语言无关的squid二级代理
python客户端调用示例
from client.py_cli import ProxyFetcher
args = dict(host='127.0.0.1', port=6379, password='123456', db=0)
# 这里`zhihu`的意思是,去和`zhihu`相关的代理ip校验队列中获取ip
# 这么做的原因是同一个代理IP对不同网站代理效果不同
fetcher = ProxyFetcher('zhihu', strategy='greedy', redis_args=args)
# 获取一个可用代理
print(fetcher.get_proxy())
# 获取可用代理列表
print(fetcher.get_proxies()) # or print(fetcher.pool)
更具体的示例见examples/zhihu
squid作为二级代理
- 安装squid,备份squid的配置文件并且启动squid,以ubuntu为例
sudo apt-get install squid
sudo sed -i ‘s/http_access deny all/http_access allow all/g’ /etc/squid/squid.conf
sudo cp /etc/squid/squid.conf /etc/squid/squid.conf.backup
sudo service squid start
- 根据操作系统修改项目配置文件config/settings.py中的
SQUID_BIN_PATH、SQUID_CONF_PATH、SQUID_TEMPLATE_PATH等参数 - 启动
squid conf的定时更新程序sudo python squid_update.py
- 使用squid作为代理中间层请求目标网站,默认代理URL为’http://squid_host:3128’,用Python请求示例如下
import requests proxies = {'https': 'http://127.0.0.1:3128'} resp = requests.get('https://httpbin.org/ip', proxies=proxies) print(resp.text)
Docker部署
-
安装Docker
- 安装docker-compose
pip install -U docker-compose
- 修改settings.py中的
SPLASH_URL和REDIS_HOST参数# 注意,如果您使用master分支下的代码,这步可被省略 SPLASH_URL = 'http://splash:8050' REDIS_HOST = 'redis' - 使用docker-compose启动各个应用组件
docker-compose up
这种方式会一同部署squid,您可以通过squid调用代理IP池,也可以使用客户端调用,和单机部署调用方式一样
注意事项
- 本项目高度依赖Redis,除了消息通信和数据存储之外,IP校验和任务定时工具也使用了Redis中的多种数据结构。 如果需要替换Redis,请自行度量
- 由于GFW的原因,某些网站需要通过科学上网才能进行访问和采集,如果用户无法访问墙外的网站,请将rules.py
task_queue为SPIDER_GFW_TASK和SPIDER_AJAX_GFW_TASK的任务enable属性设置为0或者启动爬虫的时候指定爬虫类型为common和ajaxpython crawler_booter.py –usage crawler common ajax
- 相同代理IP,对于不同网站的代理效果可能大不相同。如果通用代理无法满足您的需求,您可以为特定网站编写代理IP校验器
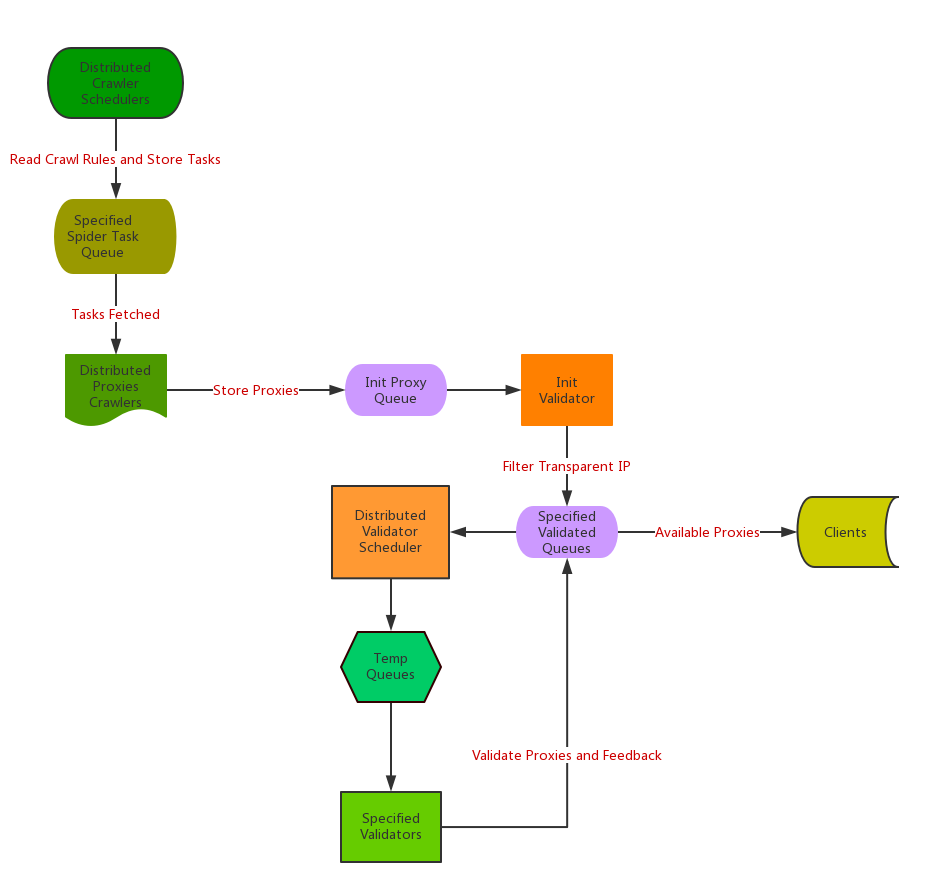
工作流程
效果测试
以单机模式部署haipproxy和测试代码,以知乎为目标请求站点,实测抓取效果如下
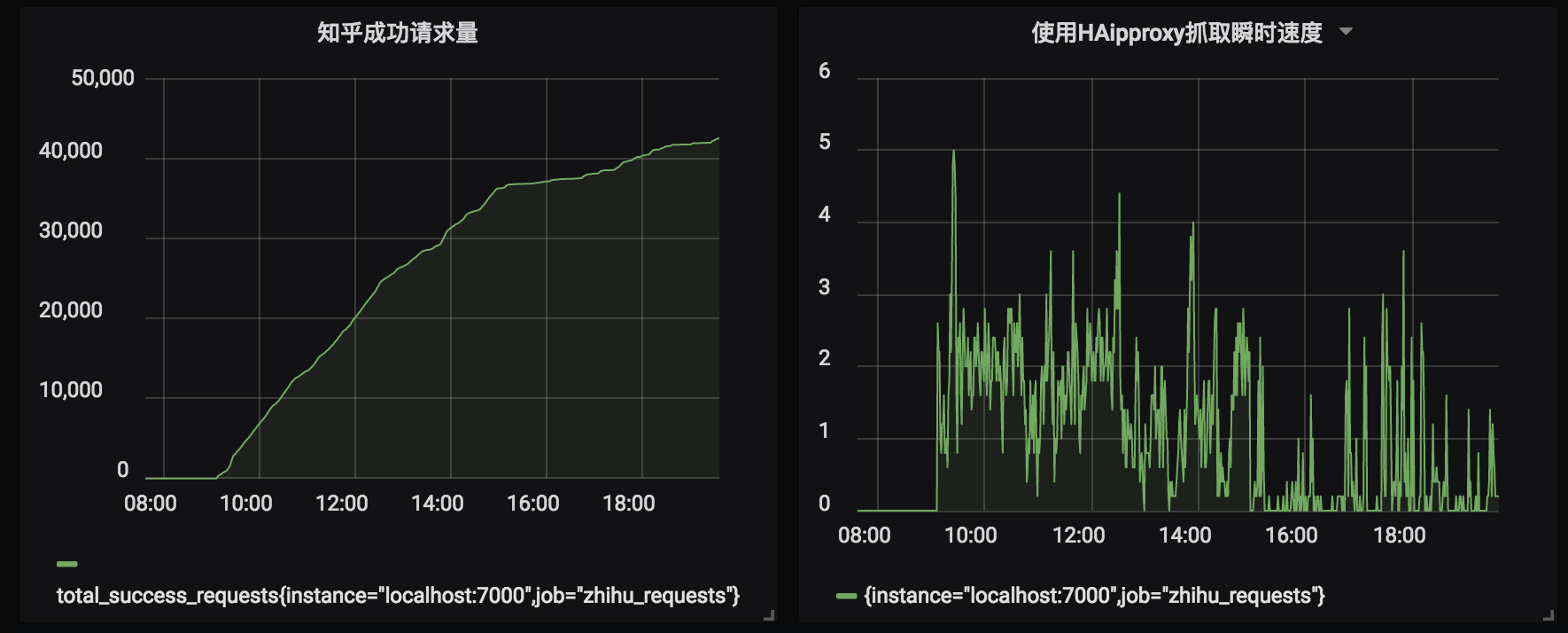
测试代码见examples/zhihu
项目监控(可选)
项目监控主要通过sentry和prometheus,通过在关键地方 进行业务埋点对项目各个维度进行监测,以提高项目的鲁棒性
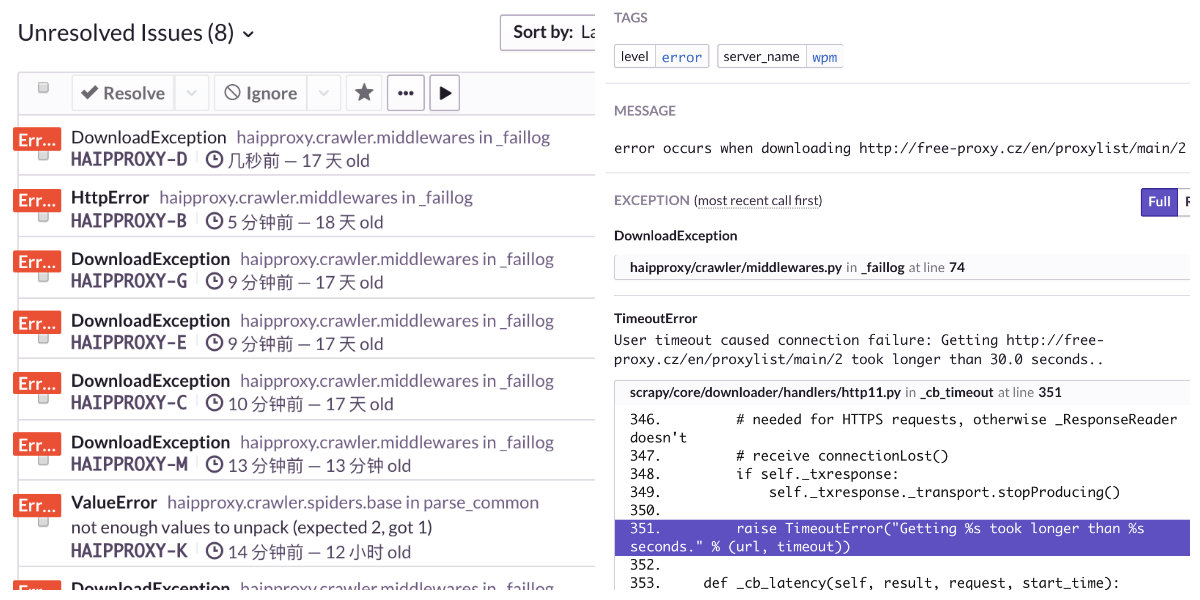
项目使用Sentry作Bug Trace工具,通过Sentry可以很容易跟踪项目健康情况
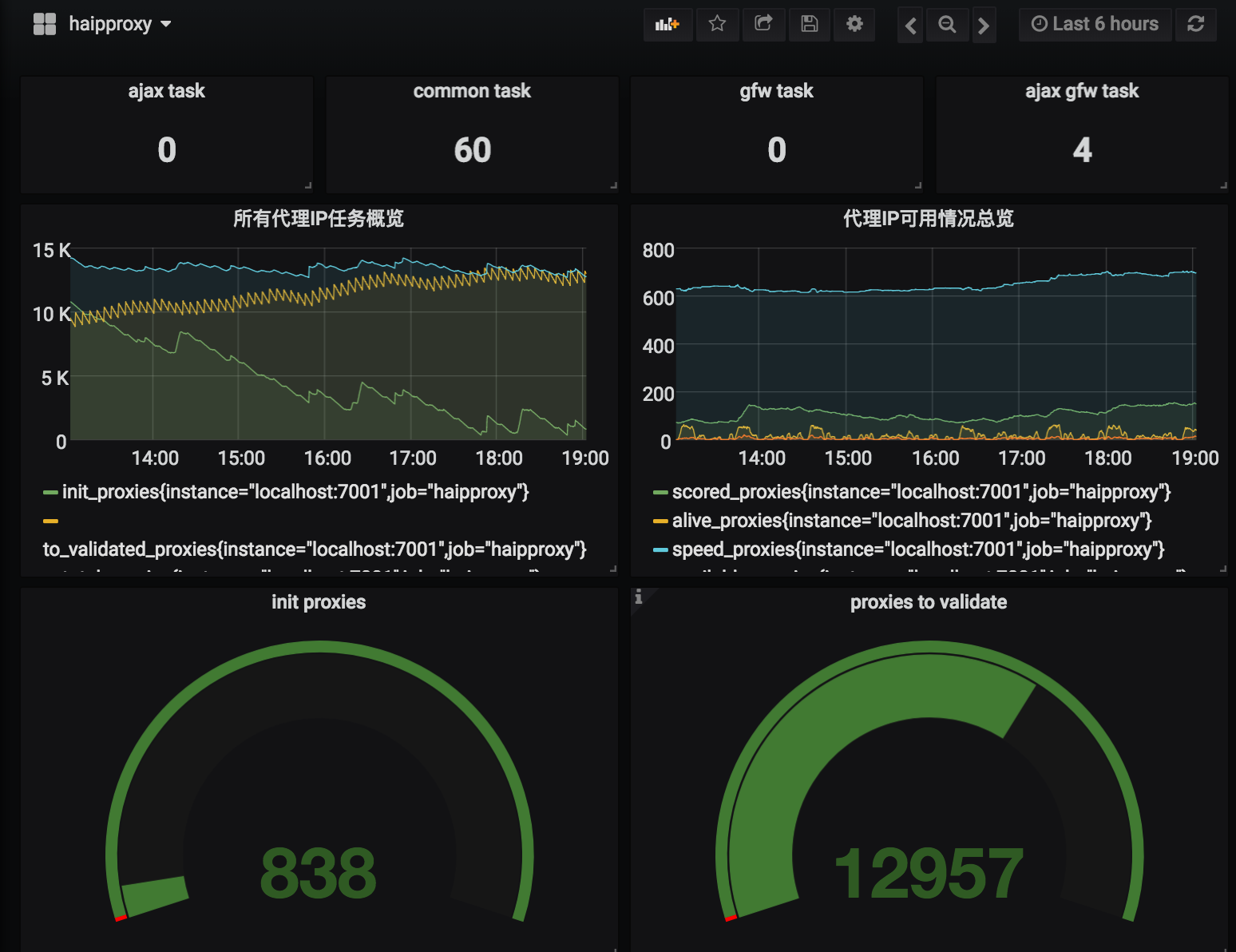
使用Prometheus+Grafana做业务监控,了解项目当前状态
捐赠作者
开源不易,如果本项目对您有用,不妨进行小额捐赠,以支持项目的持续维护

同类项目
本项目参考了Github上开源的各个爬虫代理的实现,感谢他们的付出,下面是笔者参考的所有项目,排名不分先后。