HAipproxy
This project crawls proxy ip resources from the Internet.What we wish is to provide a anonymous ip proxy pool with highly availability and low latency for distributed spiders.
Features
- Distributed crawlers with high performance, powered by scrapy and redis
- Large-scale of proxy ip resources
- HA design for both crawlers and schedulers
- Flexible architecture with task routing
- Support HTTP/HTTPS and Socks5 proxy
- MIT LICENSE.Feel free to do whatever you want
Quick start
Please go to release to download the source code, the master is unstable.
Standalone
Server
- Install Python3 and Redis Server
- Change redis args of the project config/settings.py according to redis conf,such as
REDIS_HOST,REDIS_PASSWORD - Install scrapy-splash and change
SPLASH_URLin config/settings.py - Install dependencies
pip install -r requirements.txt
- Start scrapy worker,including ip proxy crawler and validator
python crawler_booter.py –usage crawler
python crawler_booter.py –usage validator
- Start task scheduler,including crawler task scheduler and validator task scheduler
python scheduler_booter.py –usage crawler
python scheduler_booter.py –usage validator
Client
haipproxy provides both py client and squid proxy for your spiders.Any clients about any languages are welcome!
Python Client
from client.py_cli import ProxyFetcher
# args are used to connect redis, if args is None, redis args in settings.py will be used
args = dict(host='127.0.0.1', port=6379, password='123456', db=0)
# https is used for common proxy.If you want to crawl a customized website, you'd better
# write a customized ip validator according to zhihu validator
fetcher = ProxyFetcher('https', strategy='greedy', redis_args=args)
# get one proxy ip
print(fetcher.get_proxy())
# get available proxy ip list
print(fetcher.get_proxies()) # or print(fetcher.pool)
Using squid as proxy server
- Install squid,copy it’s conf as a backup and then start squid, take ubuntu for example
sudo apt-get install squid
sudo sed -i ‘s/http_access deny all/http_access allow all/g’ /etc/squid/squid.conf
sudo cp /etc/squid/squid.conf /etc/squid/squid.conf.backup
sudo service squid start
- Change
SQUID_BIN_PATH,SQUID_CONF_PATHandSQUID_TEMPLATE_PATHin config/settings.py according to your OS - Update squid conf periodically
sudo python squid_update.py
- After a while,you can send requests with squid proxies, the proxies url is ‘http://squid_host:3128’, e.g.
import requests proxies = {'https': 'http://127.0.0.1:3128'} resp = requests.get('https://httpbin.org/ip', proxies=proxies) print(resp.text)
Dockerize
-
Install Docker
- Install docker-compose
pip install -U docker-compose
- Change
SPLASH_URLandREDIS_HOSTin settings.py# notice: if you use master code, this can be ignore SPLASH_URL = 'http://splash:8050' REDIS_HOST = 'redis' - Start all the containers using docker-compose
docker-compose up
- Use py_cli or Squid to get available proxy ips.
from client.py_cli import ProxyFetcher args = dict(host='127.0.0.1', port=6379, password='123456', db=0) fetcher = ProxyFetcher('https', strategy='greedy', length=5, redis_args=args) print(fetcher.get_proxy()) print(fetcher.get_proxies()) # or print(fetcher.pool)
or
import requests
proxies = {'https': 'http://127.0.0.1:3128'}
resp = requests.get('https://httpbin.org/ip', proxies=proxies)
print(resp.text)
WorkFlow
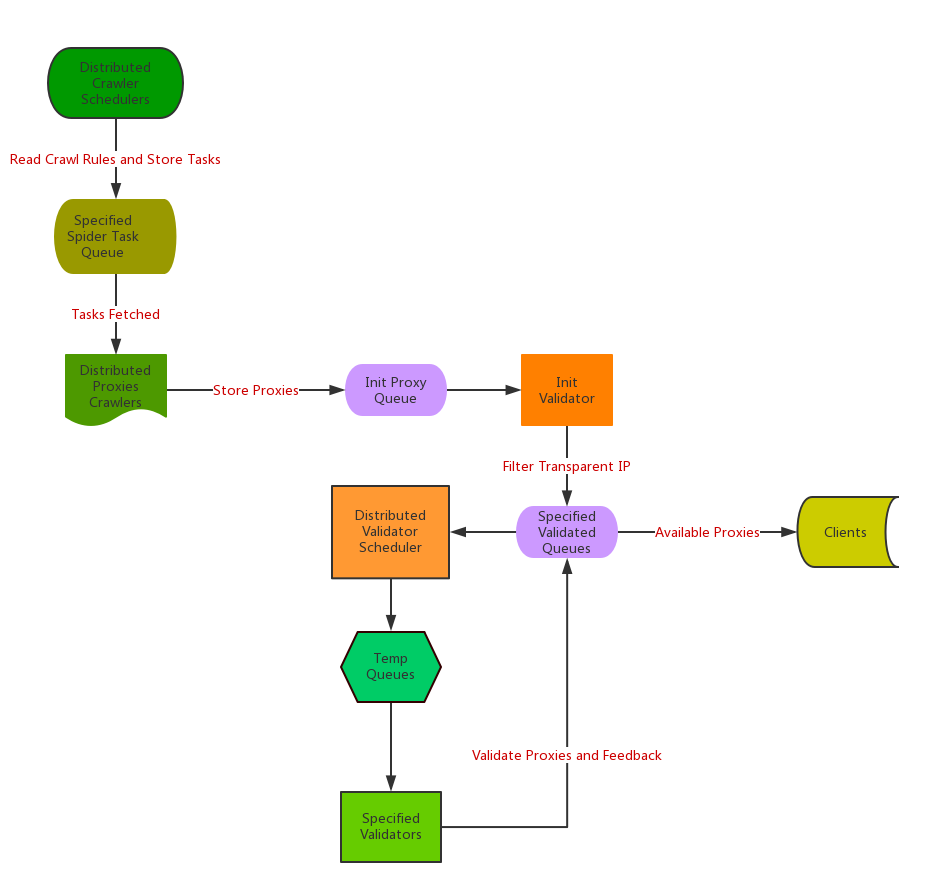
Other important things
- This project is highly dependent on redis,if you want to replace redis with another mq or database, just do it at your own risk
- If there is no Great Fire Wall at your country,set
proxy_mode=0in both gfw_spider.py and ajax_gfw_spider.py. If you don’t want to crawl some websites, setenable=0in rules.py - Becase of the Great Fire Wall in China, some proxy ip may can’t be used to crawl some websites such as Google.You can extend the proxy pool by yourself in spiders
- Issues and PRs are welcome
- Just star it if it’s useful to you
Test Result
Here are test results for crawling https://zhihu.com using haipproxy.Source Code can be seen here
| requests | time | cost | strategy | client |
|---|---|---|---|---|
| 0 | 2018/03/03 22:03 | 0 | greedy | py_cli |
| 10000 | 2018/03/03 11:03 | 1 hour | greedy | py_cli |
| 20000 | 2018/03/04 00:08 | 2 hours | greedy | py_cli |
| 30000 | 2018/03/04 01:02 | 3 hours | greedy | py_cli |
| 40000 | 2018/03/04 02:15 | 4 hours | greedy | py_cli |
| 50000 | 2018/03/04 03:03 | 5 hours | greedy | py_cli |
| 60000 | 2018/03/04 05:18 | 7 hours | greedy | py_cli |
| 70000 | 2018/03/04 07:11 | 9 hours | greedy | py_cli |
| 80000 | 2018/03/04 08:43 | 11 hours | greedy | py_cli |
Reference
Thanks to all the contributors of the following projects.